| The Self-Scaling I/O Benchmark |
| Originally published March, 1996 |
| by
Carlo Kopp |
| © 1996, 2005 Carlo Kopp |
|
One of the interesting effects we have seen in the nineties is the growing disparity between CPU and mass storage performance. Semiconductor devices, driven by Moore's law, have become smaller and thus faster, resulting in dramatic gains in performance in recent times. Storage devices, such as disk drives, constrained by Newtonian physics, have improved only modestly in access speed performance. The result has been the proliferation of compound storage systems, such as RAID arrays, which combine multiple basic storage devices to achieve performance, as well as the proliferation of multi-tiered schemes for caching data. A modern Unix platform may thus employ a complex stack of caches, implemented within the operating system, the host's hardware and the storage subsystem. Furthermore, the proliferation of networked storage schemes has added additional complexity into the modern computer system. This complexity is in turn reflected in significant difficulty in finding commonly applicable metrics for gauging performance. While some very good benchmarks exist for quantifying system compute performance, eg the SPEC series, far less effort has been expended in developing techniques for measuring, and importantly, understanding I/O performance. The practical consequence of this is that users who have important I/O performance requirements will suffer much pain in determining what I/O subsystem structure to employ, as well as in measuring and quantifying performance. Because of the enormous disparity in the size and performance of various compound I/O caching schemes, as well as disparities in throughput performance between I/O bus and adaptor and storage device type performance, trivial benchmarking methods are usually quite ineffective. The task of predicting I/O throughput performance for often very different systems can become insurmountably difficult, should we apply a trivial technique. Understanding I/O Performance To quantify the aggregate performance of an I/O subsystem we must first have some understanding of what it is that we intend to measure. For a raw storage device such as a disk defining measurable parameters is relatively trivial, in that the performance of the device can be reasonably completely defined by parameters such as the seek time, rotational latency, head bandwidth, internal cache access time and hit ratio, and interface bandwidth. Once we however install a filesystem on such a device, and hang it off a machine, things become somewhat more complicated. The first issue to be dealt with is the effect of filesystem performance, which can interact with the disk's mechanical performance in favourable or unfavourable ways. The dependency of drive performance upon filesystem type and data layout within the filesystem is not trivial and does not lend itself to simple analytical modelling. Moreover, the interaction between the drive's internal cache and the block layout scheme can also produce some interesting effects. At a system level, the effects of the operating system's block (buffer) caching scheme can be significant, in that a large and well performing cache will hide the behaviour of the I/O bus, I/O adaptor and physical storage device for small I/Os, with the inherent performance of the hardware only becoming apparent with very large I/O operations. This behaviour can be further complicated by the write caching strategy employed. Where write through caching is used, significant bus traffic and disk I/Os will be associated with all writes. Write back strategies, with infrequent syncs to disk, will conversely provide less bus traffic at the expense of robustness. Importantly, write back and write through strategies exhibit different aggregate throughput performance, and this again should be detected by any measurement technique used. Another issue which is relevant in quantifying I/O throughput performance is the degree to which consecutive operations are sequential, as this can interact both with cache performance as well as I/O device performance. Also, the number of processes concurrently executing I/O operations will impact nett performance. As a result of these factors, the I/O performance of any platform will exhibit a complex relationship with regard to both hardware and operating system performance. Any test method applied will have to be capable of analysing all of these key aspects of performance. The Self Scaling I/O benchmark performs particularly well, in this regard. The Self Scaling I/O Benchmark Established performance benchmarks generally do a poor job of analysing disk I/O performance. The SPEC suite is oriented toward CPU performance, the TPC series are transaction oriented, the SPEC/LADDIS NFS benchmark is designed for networked environments, while only the Bonnie and IOstone benchmarks are specifically oriented toward I/O throughput. Both the Bonnie and IOstone benchmarks have a number of important limitations, which limit their applicability as a general analytical tool. IOstone will access only 1 MB of data, and is thus unable to saturate a contemporary system with traffic. Bonnie touches a full 100 MB of data, but even that may not be adequate for a contemporary file server. In either instance, the central weakness lies in an inability to scale the applied workload to the system automatically. In 1993, Peter Chen and David Patterson, then both at UCB EECS, identified these limitations in existing I/O benchmark suites. They subsequently proceeded to develop a benchmark which addresses the problems discussed above (Chen P.M., Patterson D.A., Storage Performance - Metrics and Benchmarks, UCB EECS Technical Report, and Chen P.M., Patterson D.A., A New Approach to I/O Performance Evaluation - Self Scaling I/O Benchmarks, ACM Sigmetrics 1993 Conference on Measurement and Modelling of Computer Systems). This benchmark is the Self Scaling I/O Benchmark. The central idea behind the benchmark was to produce a tool which would adaptively explore the performance of the tested system, with varying workload parameters. In this fashion a single benchmark would be capable of providing useful comparisons between machines with widely ranging I/O performance, in every instance the benchmark would in effect "explore" the performance space of the tested system. The benchmark produces a workload defined by five separate parameters. The benchmark when running will find a focal point for each parameter, and then graph performance for one parameter, while all others are fixed. The result is a set of plots, which provide a indication of performance with the variation of the swept parameter. The focal point is chosen to lie at the middle of the range of any given parameter. The five parameters are :
Chen and Patterson's published test results indicate that the
benchmark yields an accuracy between predicted and measured performance
typically between 10% and 15%, with a repeatability between test runs of
about 5%. Given the nature of the measurement, these are indeed very
good figures.
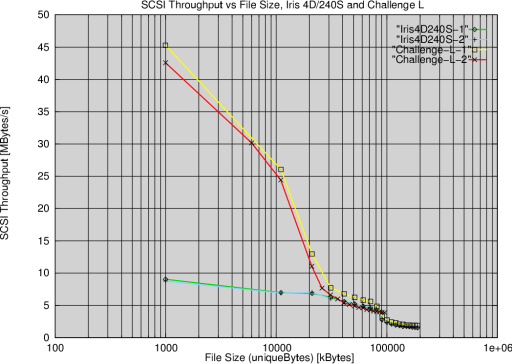
Test Results The author has had the opportunity to run the Self Scaling I/O Benchmark on a customer site, to evaluate the relative performance of a number of configurations of two machines. The context of the measurement was the relative I/O throughput performance of a Unix file server system, and its replacement system. The customer was interested in a direct comparison of I/O throughput performance between the original system and its replacement, as well as the comparison of replacement system performance when configured with additional memory and disk. The then to be retired file server was an SGI Iris 4D/240S with four 25 MHZ MIPS R2000 Processors each with a Data cache size of 64 Kbytes and Instruction cache size of 64 Kbytes, a Secondary data cache size of 256 Kbytes, and a Main memory size of 96 Mbytes. The disk array tested was a set of eight differential SCSI Fujitsu M2654HA 5.25" 2.4 GB SCSI-2 Drives, interfaced to the host with an Interphase 4210 Cougar VME-SCSI controller. The system was running Irix 4.5, which is a ported and modified System V Unix. Performance for this system is depicted in Fig.1, which contains plots of throughput in Mbytes/s for range of values of uniqueBytes, sizeMean, readFrac, seqFrac and processNum. Interpretation of these plots yields some interesting insights into system performance. The plot of processNum indicates that only two processes were actively generating workload. The readFrac plot tells us that throughput performance for large reads is si slightly better than that for writes, this is consistent with disk drives using read lookahead caching, but no write caching, on a System V host which employs a writeback cache strategy (periodic fsyncs). The seqFrac plot indicates that sequential operations offer similar throughput to random accesses. The sizeMean plot clearly shows that increasing transfer size improves measured throughput to a point, beyond which overheads diminish performance. The most revealing plot however is that of uniqueBytes, a measure of the data size transfered. This plot allows us to determine both raw filesystem/hardware performance, as well as cache performance. For small values of uniqueBytes, throughput performance is dominated by the cache in main memory. With increasing uniqueBytes, the cache hit ratio declines and hardware performance comes into play. This is particularly evident for values between 10,000 and 20,000, where indeed the characteristic is almost flat at about 7 MBytes/s. Beyond this point, the performance of the hardware dominates. At values of between 60,000 and 80,000 , the measured performance corresponds to the raw bandwidth of the disk heads. Beyond this point, performance declines due the effects of filesystem behaviour. Performance in this area is primarily limited by the need to look up indirect block pointers from the inode, thus causing frequent multiple block accesses per read. Figure 2 is a comparison of performance between the retired file server, and the replacement file server. The replacement system was an SGI Challenge L with two 150 MHZ MIPS R4400 Processor Chips, a Data cache size of 16 Kbytes, an Instruction cache size of 16 Kbytes, a Secondary unified instruction/data cache size of 1 Mbyte and a Main memory size of 128 Mbytes (2-way interleaved). The disks were attached to the system's Integral differential SCSI-2 controller (WD33C95A chips), using the identical Fujitsu disk array tested on the Iris 4D/240. The superior compute performance and memory bus bandwidth of the newer machine is clearly evident from the plot, with better than 42 MBytes/s achieved for small I/O operations hitting cache. This is about five times faster than the earlier generation machine. Once again, the benchmark clearly illustrates the decline in I/O throughput as the performance of the disk hardware becomes dominant. Figure 3 compares the relative performance of a number of configurations of the Challenge L. The system was tested with 128 MB of memory, using the older Fujitsu drive, as well as a state of the art Seagate Elite 9 GB drive. The test run for the Elite was subsequently repeated with 256 MB of main memory. Comparing the performance of the 128 MB system with the two drive types, it is quite evident that the newer drive delivers slightly better throughput performance, although not dramatically better. The outcome of the test was to retain the four 2 GB Fujitsu drives rather than use the single replacement, as the gain in performance did not justify the replacement cost of the drives. Comparing the 128 MB and 256 MB configurations yielded a similar outcome. The effect of the added memory was to delay the onset of the point at which the cache became ineffective, for the user site in question the performance gain did not justify the additional memory, which was subsequently not acquired. In the author's opinion the Self Scaling I/O Benchmark is without doubt the most potent tool yet to be developed for the I/O system designer's armoury. Used carefully, and combined with a good technical insight, this tool allows for quite exact analysis of host system I/O throughput. As a result, performance of existing systems may be analysed and tuned, or comparative performance of competing systems may be measured. In all of these situations, the Self Scaling I/O Benchmark will save money and reduce risks. |
| $Revision: 1.1 $ |
| Last Updated: Sun Apr 24 11:22:45 GMT 2005 |
| Artwork and text © 2005 Carlo Kopp |