| Programming with 64-bit Machines |
| Originally published November, 2001 |
| by
Carlo Kopp |
| © 2001, 2005 Carlo Kopp |
| |
|
Part II Arithmetic Issues
New generation 64-bit machines, be they based upon RISC technology of variants of newer VLIW technology, will require some changes in programming technique. In last month's issue Systems Developer explored portability issues in transition from established 32-bit hardware to 64-bit hardware. This month's feature will explore issues in machine arithmetic. Machine Arithmetic Machine arithmetic is a broad term used to describe the techniques used in hardware, and where applicable, microcode, to perform integer and floating point arithmetic calculations. Two parameters are of key importance to designers of arithmetic hardware (and microcode). These are speed and accuracy. Speed is simply a measure of how quickly the machinery can complete a specific category of arithmetic operation, such as an ADD, SUB, MUL, DIV, SHIFT or other operation. Obviously, the faster the better, and speed usually reflects in the price of the hardware. Accuracy is measure of the error introduced as a result of the arithmetic operation. While many integer operations are exact, floating point operations are frequently inexact. To place this into context, digital computers manipulate binary numbers. The numbers we work with in our daily lives are decimal integers or fractions. We can represent a fraction exactly on paper, eg 1/2, 1/4, 1/23 and so on, but if we are to represent them as decimal numbers the representation is frequently inexact. While 1/2 can be accurately represented as 0.5, 1/4 as 0.25, 1/23 is represented as 0.04347826.... which is not exact. Novices to the computing world frequently have difficulty with the idea of using a representation rather than the number itself. If the representation is good enough, the difference between the exact value and the representation should be small enough not to matter. Since computers perform arithmetic in binary, exact or fractional decimal representations have to be converted into a binary value before the computer can perform arithmetic. This is done by I/O software, for instance the stdio library in C which incorporates extensive format conversion routines for numerical I/O. Digital computers, and binary machines are no exception, have
inherent limitations in the size of the numbers which they can
represent. Consider integer arithmetic on machines with the following
word (integer) sizes:
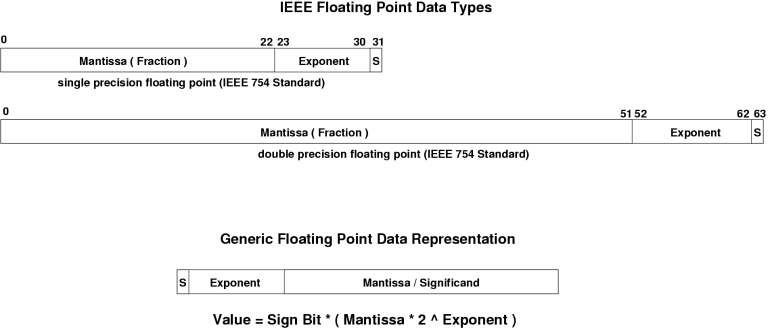
If we aim to represent a number larger than the integer size of the machine, then we have to start playing tricks like using double-words or performing the arithmetic using a software library which emulates decimal or other arithmetic. Alternately, we can avoid the problem by representing the number in floating point format rather than integer, and accept a loss in accuracy resulting from the conversion to a floating point format. The key to successfully mastering machine arithmetic, either as a designer or as a user of the machine, is to understand the limitations of the represntation being used and the errors introduced by both representation and arithmetic. If these are understood well, then their impact on the behaviour of the algorithms in which these calculations are used can be objectively assessed. One might ask the question why does this matter? Poor management of representation and arithmetic errors can produce no end of mischief in a program, or indeed in a system which uses that program. A very common problem is halting or exiting from a loop or iteration, in which a particular condition needs to be met. A trivial for loop in which an integer loop count is incremented or decremented always behaves (if done properly). What happens however if this is a do-while loop in which the equality of two floating point values is tested to determine the end of the loop (amd halt)? The usual way in which we perform such a test is to subtract the two values and see if the result is zero. In practice this method breaks, since subtracting two almost identical floating point numbers inevitably leaves some tiny residue which is of course - a non-zero value. As a result the program loops forever. Hardware for integer arithmetic is conceptually simple. An arithmetic unit takes two integer values and using an appropriate collection of digital logic and embedded algorithm, produces the result of the calculation. An addition of two integers produces a bigger integer, a substraction of two a smaller integer. Multiplication of two integers produces an integer with twice as many bits. Simple? Not quite. The problem we have to manage here is termed arithmetic overflow, and this arises when the result of the calculation is too big to represent as an integer on the machine in question. Assume we aim to add 1111B and 1111B on a 4 bit machine. The result is 11110B which is too big to fit. This condition is termed an overflow and a flag bit in the CPU is set when this occurs, so the software can manage the condition. So far we have briefly looked at the limitations in integer representation on binary machines. Basically, the bigger the word size of the machine, the bigger the integers it can represent. With few exceptions, a 32 or 64 bit machine can handle almost any problem we might need to tackle. The few exceptions are a class of their own. Floating point representation is a different game (readers are referred to David Goldberg's excellent tutorial What Every Computer Scientist Should Know About Floating Point Arithmetic available at http://www.acm.org/ .). In floating point, a number is represented by the product of a fraction of two and a power of two, or M x 2^E. We call the fraction the Mantissa (M) and we represent the power with the Exponent alone since the value of 2 is redundant. This is analogous to decimal floating point representation. An example binary floating point number might be 0.10111011001 x 2^1011. Floating point numbers are inherently inexact. This is because there are a infinite number of real numbers between any two real numbers, yet we have a finite number of bits into which we can store the floating point representation of any real number. The floating point representation has two components, the
mantissa and the exponent. The size of the mantissa determines how
accurately we can represent the real number; the size of the exponent
determines how large or how small a real number we can represent. Refer
Figures 1 and 2.
Most modern machines are compliant with the IEEE 754 floating point standard. Thsi standard supports four representations with differing accuracies:
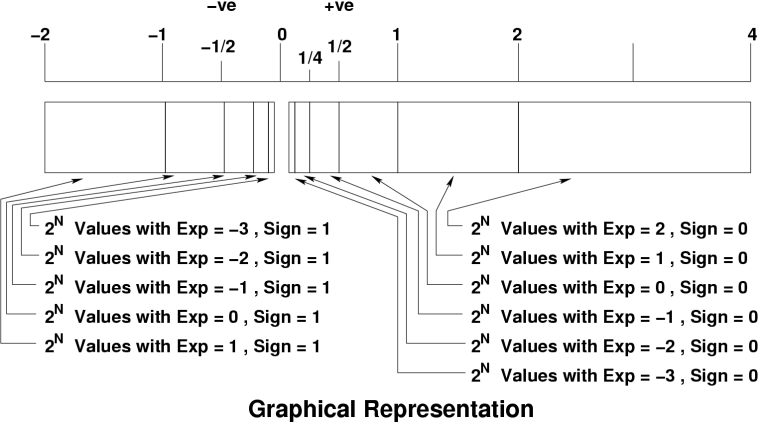
The actual size of the IEEE mantissas may be listed as one bit larger than cited, since the standard permits the use of an additional hidden guard bit to improve accuracy. How large the error is in representing an arbitrary real number is determined by how many bits would be needed in a mantissa which accurately represents the real, against the actual size of the mantissa. Consider this example: Accurate representation is 0.111111111111 x 2^0. Actual representation is 0.11111111 x 2^0. The difference is then in the last several bits of the number, i.e. 0.000000001111 x 2^0. Clearly the dominant bit in the error term is the leftmost bit, after the 8 bits which represent the real number. The bits which follow it are respectively 1/2, 1/4, 1/8 etc the size of the leading error bit and are thus less important. The obvious conclusion is that the last bit in the floating point representation is the one which matters since it largely determines how big the error between the representation and the actual real number is. Another issue of importance in floating point arithmetic is the idea of normalisation. A normalised floating point number is one in which the bit before the binary point is zero. An arbitrary floating point number is normalised by shifting the point either left or right until the first bit following the binary point is 1, while the exponent is either decremented or incremented by the number of bits in the operation. Normalised representation is useful since it maximises the number of valid bits in the representation, and thus makes the best possible use of the bits in the mantissa. The Impact of Floating Point Errors Very frequently the accuracy of even single precision floating point arithmetic is adequate for the purpose at hand. C compilers will typically convert all single precision float variables into double precision, simply to preclude any problems arising. Accuracy does however become quite critical in calculations which manipulate small numbers, especially where these tend to zero. Many algorithms used in matrix arithmetic rely on bits being zeroed in the calculation, and residual errors can interfere with the behaviour of the algorithm. Addition of two floating point numbers can produce interesting effects. If the exponents of the two numbers are the same, and both are normalised, then the two mantissas are added, and the result is then renormalised. At most the renormalising operation chops one bit off the end of the result mantissa, producing little impact on accuracy. What if the two numbers to be added differ largely in relative size? An example might be one number with an exponent many times larger than the other. To perform an addition, the binary points in these numbers must be aligned. This means making the value of both exponents the same, by denormalising one or both numbers. Consider a trivial case in which the mantissa is 8 bits long and the exponents differ by 7. Denormalising the smaller number will result in seven right shifts which will push 7 of the significant bits in the number out of the mantissa altogether. From an intuitive perspective, this is simply because the smaller number is similar in relative magnitude to the least significant bit in the larger number! This effect is termed underflow. The finite size of the mantissa can produce a situation where the smaller of the two numbers being added (or subtracted) is effectively reduced to zero. The fix for this is to use a larger mantissa, if possible. A related effect with similar consequences can also occur where multiple or chained additions of operands must be performed, where the operands differ greatly in relative size. This is best illustrated by example. Assume that a dozen operands need to be added together. Assume then that these are sorted by relative size, starting with the largest and ending with the smallest. First we perform the addition by starting from the largest operand and finishing with the smallest one. The first two numbers are added producing a partial sum, which is larger than either of the two operands added to produce it. Adding the third operand to the partial sum, we find that the error in the addition is larger than it would have been had we added the third operand to either the first or the second operand. Indeed, adding from the largest to the smallest we find that the difference in size between the partial sum and the next operand keeps increasing, and the error in the calculation gets increasingly larger. On the other hand, if the summation of the operands is performed starting with the two smallest operands, the size of the partial sum relative to the next operand to be added is minimised, and the error is thus minimised. The important caveat here is that the order in which floating point operands are added does matter and programmers who fail to heed this reality will get bitten. It is unsafe to assume that a compiler or library will have the smarts to reorder operands in a multiple or chained summation. Indeed, at compile time there may be no obvious cue as to the relative size of the operands. The cautious programmer will explore the dataset before coding to see whether such a problem might arise, and if need be then write the algorithm to sort the operands by size and then add them in the proper order to minimise the resulting error in the calculation. Floating point multiplication operations are more forgiving, mostly. When the two normalised mantissas are multiplied out and the exponents are added, the mantissa in the result will inevitably have leading zeroes. The number therefore needs to be renormalised again. Whil ordering in a multiplication does not matter, the multiplier hardware should include an extra guard bit to preserve the least significant bit of the result before it is renormalised. One consideration which is frequently neglected is the effect of error scaling, which arises whenever two floating point numbers are multiplied. A trivial example is where a real number which is represented in floating point format, and the representation is inexact. For the purpose of argument, let us assume the error is precisely one half bit. If this number is multiplied by say 16 or 65536, then that error is also multiplied in size exactly 16 or 65536 times. Where the error in a flaoting point representation does in the calculation, and the number will be multiplied by numbers much greater than one, some thought should be given to the scaling of error magnitude. While the oddities of addition and the limitations of binary representation are the most obvious problems which might be encountered, they are not the only ones. A frequent problem which might arise is divide by zero. In the world outside digital computers, dividing any finite number by zero yields infinity, which cannot be represented on a digital computer (or arguably in any finite form). Floating point hardware is usually designed to detect a divide by zero condition. Typical floating point hardware will identify operands which are inappropriate as Not a Number or NaN. The hardware will then cause a trap or an exception to a piece of code which handles the condition. A core dump or BSOD may follow. Getting the Most Out of the Hardware Most of the gotchas in programming with floating point arithmetic, or integer arithmetic, described are classical show stoppers and will cause the malfunction or indeed crashing of a program on an arbitrary piece of hardware, whether it is 16-bit 10 MHz clunker or a 1.8 GHz 64-bit hot rod. Most hardware built over the last decade conforms either completely or largely to the IEEE 754 standard. The IA-64 for instance nominally meets IEEE 754 with a single, double and extended double precision format, the latter with a 64 bit mantissa and 15 bit exponent, occupying a full 80 bits for the operand. The key caveats with numerical computing always apply and a well written application should typically port across architectures with no difficulty. It does however pay to carefully validate the robustness of an algorithm or a library when it is ported across hardware boundaries to ensure that no mutually disagreeable assumptions were made at either end. In terms of maximising application performance, where high levels of numerical accuracy are required in the arithmetic, there is no trivial answer. The behaviour of the application should be carefully explored, and if the algorithm can be manipulated in a manner which improves Instruction Level Parallelism over short runs of instructions, the odds are than some performance gain might be realised. Since these days numerical computing and the finer points of floating point arithmetic, pun intended, are usually taught as electives in University Comp Sci and Engineering courses, beginners in this area are cautioned to tread carefully. A bit of reading up before one starts coding can save a considerable amount of heartache. |
| $Revision: 1.1 $ |
| Last Updated: Sun Apr 24 11:22:45 GMT 2005 |
| Artwork and text © 2005 Carlo Kopp |