| INFINIBAND |
| Originally published September, 2001 |
| by
Carlo Kopp |
| © 2001, 2005 Carlo Kopp |
|
The advent of GigaHertz class processors has profound implications for the industry. Memory and I/O bandwidth is becoming very much the bottleneck in the achievable performance of computer systems, be they humble desktops or grandiose servers. Traditionally, memory and I/O bandwidth performance was the parameter which distinguished mainframes, large Unix servers, and Unix workstations from the Intel architecture PC. While this gap has narrowed in recent years between workstations and PCs, the mainframes and large servers continued to hold an unassailable lead in the market. With the advent of the Internet, we saw a distinct split in I/O architectures, with storage devices continuing to use mostly parallel interfaces and networks by default using serialised interfaces. Internally, small and medium sized machines continued to use traditional bussing, while large servers and workstations shifted progressively toward switched parallel architectures. If we delve into the bowels of a contemporary desktop PC, the odds are very good that what we will find is a very traditional model.
This is by any measure a fairly complex arrangement of busses and interfaces, widely varying in terms of throughput but also in terms of addressing modes and capabilities. The vital DMA (Direct Memory Access) capability is usually supported only by parallel busses, although the Firewire serial bus provides similar functionality. Moving up to a large server, the odds are very good that it will employ an array of processor boards, each of which uses an internal parallel switch to interconnect the CPU and on-board memory controller, and some parallel interface to a system level switching scheme to connect to the bulk main memory and main I/O controllers. In turn, the I/O controllers are apt to be using PCI or proprietary parallel busses to accommodate diverse adaptor boards, repeating the low level I/O interface model we see in desktops. The sad reality is that what we find either in a desktop or a server is a veritable babel of bussing and interface standards, each with unique strengths and limitations, both in supported modes of transfer and in achievable throughput. Evolution has produced what is at best untidy and at worst very cumbersome. Some interfaces, such as the serial RS-232C/RS-423 have little functionality and performance, but are vital to support legacy I/O devices. Some, such as SCSI and IDE/EIDE are supported almost exclusively by disks, tapes, CD-ROMs, DVDs and other bulk I/O devices - despite the much more ambitious aims of the SCSI standard. This untidiness is also found in CPU bussing and main system busses, and frequently also in main memory array busses. Proprietary interfaces are arguably dominant in this area of technology. What does this mean for the hapless developer?
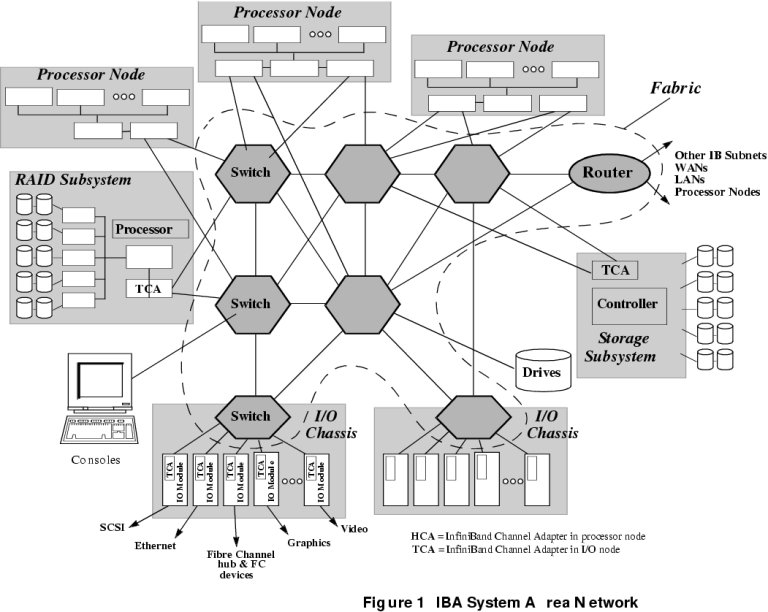
With the strong prospect of rapid evolution in CPU and I/O device technology, in coming years, and a push for increased availability of highly parallel processing, the complexity we see in current generation hardware is at best a serious nuisance and at worst an impediment to growth. One of the holy grails of the modern computing technology base is portability. Portability has two sides, longitudinal portability which is more commonly known under the buzzword of backward compatibility, and horizontal portability which is a more formal way of describing cross-platform portability. Poor portability costs money, all of which hurts developers and ultimately has to be paid for by consumers. It is a sad fact of life that most of the portability problems we see today are a direct consequence of hardware and software vendors using proprietary interfaces to lock clients into their products at the expense of competitors. This is not a new phenomenon, indeed 70 years ago a consumer buying a car may have faced the reality of everything down to screws and other fasteners being vendor specific. At this time applications are very frequently wedded by library interface standards to specific operating systems, which in turn wed them to specific hardware platforms. Developers and end users are frequently burdened with using hardware which they do not like to accommodate applications which they must support. Much better standardisation in hardware interface standards does not solve this problem, but it does alleviate it to a large degree. The most recent attempt to unify bussing and interface standards is perhaps the most ambitious seen to date. The International Data Corporation (IDC) InfiniBand (http://www.infinibandta.org/home.php3) stands a very good chance of changing the paradigm. IDC InfiniBand The International Data Corporation is an industry consortium which was created in 1999. The Next Generation I/O (NGIO) group led by Intel and the Future I/O (FIO) group, led by IBM, Compaq and HP, merged to form initially the InfiniBand Trade Association (IBTA). Further players joined the new grouping, which is now led by seven steering members - IBM, Intel, Compaq, HP, Dell, Microsoft and Sun Microsystems, and supported by sponsoring members, who include 3-Com, Adaptec, Cisco, Fujitsu-Siemens, Hitachi, Lucent, NEC and Nortel. Importantly, this consotium encompasses the largest players in the desktop, server, I/O and networking hardware markets. The fundamental aim of the InfiniBand grouping is to produce a unified model and interconnection standard for processors, memory and I/O devices, which would wholly supplant the vast range of high speed serial and parallel interfaces currently found across the market. This common interface scheme would be employed in systems of all possible sizes, from compact desktops up to sprawling mainframes. The InfiniBand model diverges aggressively from all previous attempts to standardise CPU, I/O and memory bussing schemes. Rather than using the traditional parallel bussing model, InfiniBand is based upon a switched fabric model. In a basic switched model, multiple devices, be they CPUs, Memory Controllers or I/O Controllers, are all connected to a central high speed switching device. When a device needs to transfer data to or from a peer, it tells the switch what its source/destination device is and the switch makes an internal point-to-point connection between the two devices. A good switch allows concurrent transactions to take place between multiple devices, unlike a bus which is always wholly committed to the single transfer in progress. As a result a switched model can potentially achieve much better throughput than a bussed model. This is not unlike the performance gains seen with a switched 10-Base-T Ethernet over a conventional coaxial Ethernet. The limitation of a basic switched model is that the switching device must become increasingly larger and more complex as the number of supported devices increases. This sets very practical limits on what the size and complexity of such switched systems can be. An alternative strategy is a switched fabric in which multiple switches are cascaded to provide, in effect, any interconnection topology which is desired. This model allows the size of the switching fabric to be increased by adding more switches, and the acheivable throughput and delay to be manipulated by the interconnection topology between switches. The InfiniBand Architecture (IBA) standard uses the switched fabric architecture for interconnections between devices inside chassis, but also for interconnections between chassis. It thus aims to remove the distinction between in-chassis and external interfaces - the same model and interface is used for all devices. Whether they are CPUs, memory controllers, I/O controllers, storage arrays or devices, routers or other networking devices, they all connect via the same switched fabric (Refer Figure 1.). In practical terms this results in a scheme where every I/O adaptor, every storage device, every CPU/Memory module and every bulk main memory can be mixed and matched by need since they all share a common interface. Moreover, server boxes can be mixed and matched with I/O boxes such as RAID arrays, routers or network switches. An important feature of the IBA is that it provides reliable interconnections between devices, supporting both messaging and remote DMA operations, without the intervention of the operating system software. The addressing models and the transfer modes are wholly supported in the hardware interface. Since one of the aims of the IBA is to support legacy operating systems and applications, as well as newer creations, it incorporates protection mechanisms for the respective address spaces of processes sending and receiving data. Therefore a kernel or process running in kernel mode can safely read and write to I/O, while a user process may be restricted to reading and writing shared address spaces with other user processes. This is model which has the potential to much simplify the traditionally painful area of interprocess communications. The need to accommodate legacy hardware and software is reflected in the IBA model, in that manufacturers have the option of a gradual transition, in which their hardware may support IBA interfaces in addition to more established interfaces. While this is apt to prolong the life of the existing interface hardware standards Babel, it does mean that users with a large investment in legacy hardware are not necessarily left out in the cold. The use of both in-chassis and box-to-box interfaces allows considerable flexibility in the integration of systems. In terms of bandwidth, the IBA standard aims to remain an order of magnitude faster than the established SCSI, Fiber Channel and Ethernet standards families. To facilitate integration with networking hardware, the IBA standard supports the native use of IPv6 header structures. The overheads of running traffic in and out of a network are thus much reduced against established hardware. The InfiniBand Architecture Release 1.0.a is a voluminous
document, occupying two multi-Megabyte PDF files. It was released on the
19th June, 2001, and the following discussion will aim to summarise its
most important features.
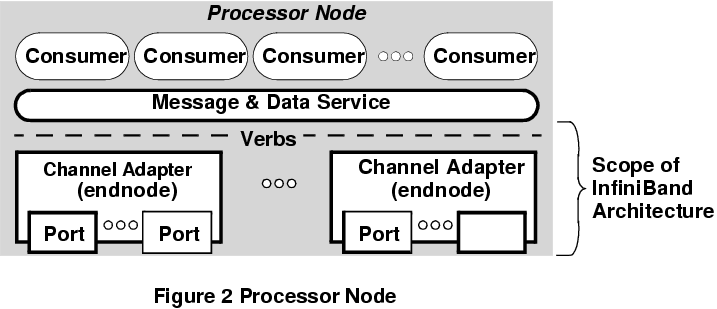
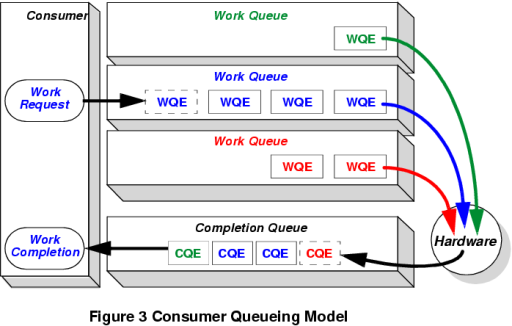
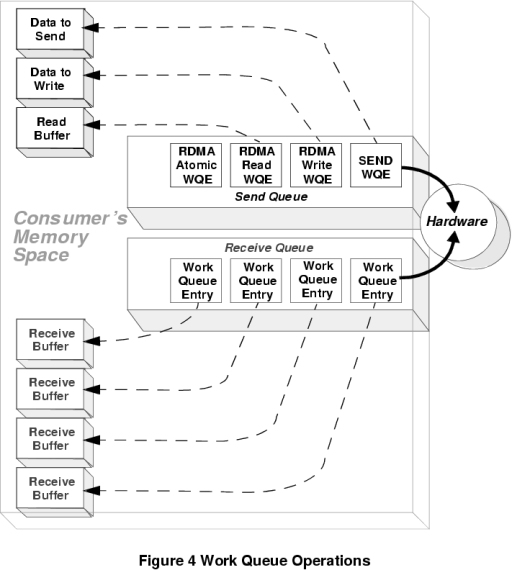
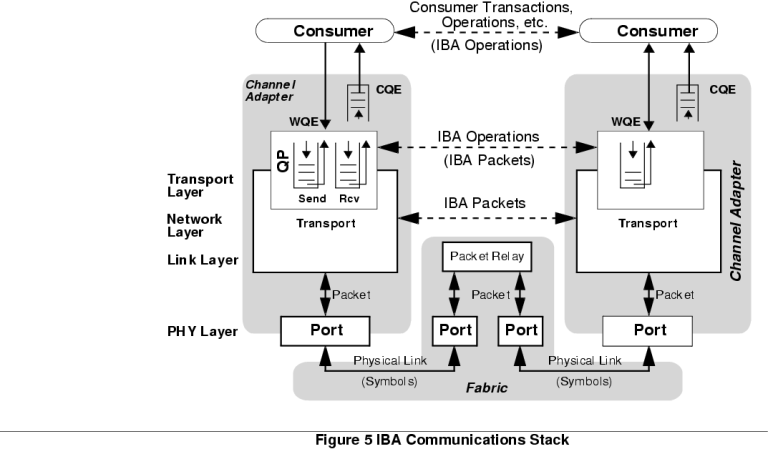
The InfiniBand Architecture The much overused abbreviation SAN is now a part of the IBA lexicon, standing for System Area Network, the basic model used for the IBA fabric. The basic topology for a SAN is an IBA fabric which interconnects many nodes, each of these being a device with an IBA interface. The fabric itself comprises multiple IBA subnets, which may be interconnected by routers. Each IBA subnet, in turn, comprises one or more IBA switches with some arbitrary interconnection topology. In this manner, IBA fabrics of almost arbitrary complexity and aggregate throughput can be constructed, from the trivial instance of two IBA nodes connected directly, to fabrics with dozens or hundreds of nodes connected. Each node connected to an IBA fabric is a single IBA channel adaptor. Therefore a processor/memory box may appear as multiple IBA nodes by virtue of having multiple IBA adaptors installed, refer Figure 2. The software interface is simple, by design. The IBA model is based upon a queued messaging protocol, and provides a management interface and a data transfer interface. Application processes, and kernels if necessary, communicate with an IBA channel via a Message and Data Service layer, which provides a clean interface to the entity accessing the channel. In practice, the Message and Data Service layer could be implemented as a library, or it could be embedded in a kernel as a driver. Indeed, a Unix implementation would probably appear as a character device driver to provide transparency to network protocol implementations and storage device drivers. Suffice to say, the simple interface is unlikely to result in any unreasonably difficult implementation problems in Unix environments. In IBA-speak, an entity using the channel is termed a consumer. The IBA model is built around the idea of Work Queues - transfers over the IBA channel are queued by a consumer when sending, and read from a queue when receiving. This model provides a tidy asynchronous interface to the consumer. When the consumer wishes to send it puts the messages on a queue, when ready to recieve it reads them off a queue. Work queues are always created in pairs, one for sending and one for receiving. In this model, the consumer will use the send queue for instructions which transfer data from the consumer's memory to the memory of another consumer. The receive queue contains incoming data and instructions which specify where the data is to be placed in the memory of the receiving consumer. There is some assymmetry in this model - a Host Channel Adapter (HCA) has behaviour specified by the IBA standard, unlike I/O device adapters which may exhibit proprietary behaviour (no doubt a concession forced by the I/O device makers in the consortium). Readers may have noted that the queueing model described does not contain a mechanism for signalling the completion of the transfer. This mechanism is implemented in the IBA model as a Completion Queue. When the IBA hardware completes a receive or send operations, it places a Completion Queue Element (CQE) on the Completion Queue, in the same manner as a Work Queue Element (WQE) is placed on the Work Queue by a consumer. Completion Queues may or may not be shared by Work Queues. Refer Figure 4. The IBA standard supports three categories of send queue operation, citing from the IBA spec:
The only receive queue operation supported is a RECEIVE WQE which speciifies where the hardware is to place data received from another consumer when that consumer executes a SEND operation. This simple and elegant model allows the IBA interface to support both classical I/O transfers but also facilities such as shared memory between multiple hosts connected to the fabric. In operation a process, or a thread within that process, can poll the queues to determine their state and thus avoid the traditional difficulties seen with blocking I/O. If the process is waiting for the completion of the I/O, it can poll the queue and if incomplete, relinquish its time slice and poll again at the beginning of the next time slice. This model is well tuned to large multiprocessor systems - it is not optimised for real time systems. Figure 5 depicts the protocol stack for the IBA. A more detailed discussion of the protocol and data packet formats is best left for a future article. InfiniBand Hardware Interfaces The IBA standard at this time supports three basic interface formats:
While the backplane port supports a full set of the signals, the cable and fibre ports support only a subset. In the 1.0 release of the IBA standard, the maximum supported throughput is 2.5 Gigabits/s, which approximates to about 250 Megabytes/s of effective throughput, this is supported by all interfaces. The stated aim is to support higher speeds in future IBA versions. All IBA interfaces are serial using the 8B/10B encoding scheme common to Fibre Channel and Gigabit Ethernet, however, the IBA model supports multiple lanes or parallel transmission paths. The data is then striped across these lanes to increase the throughput for a given clock speed. Three arrangements exist, termed 1X, 4X and 12X with 2, 8 and 24 differential pairs or optical fibres in the receive and transmit directions respectively. In addition the copper variants use additional power lines, and all use additional management and clocking signals. The backplane connectors are of a new design, in either a 1X/4X format or larger 12X format, depending on the number of lanes used. The latter has a hefty 48 paired high speed contacts and 18 low speed/power contacts. The nominal impedance of the pairs is 100 Ohms, and there is a comprehensive requirement for impedance matching in the IBA standard (a feature sorely missed in older standards). Unlike many older standards, IBA defines eye pattern diagrams for all interfaces. The 1X copper cable standard employs a new Fibre Channel style connector format, with 7 pins. The 4X standard uses an 8 pair MicroGigaCN connector, and the 12X standard a 24 pair MicroGigaCN connector. The optical variants of IBA are equally comprehensive in definition, using 1, 4 or 12 fibres in either direction. The 1X variant uses an LC connector, the 4X and 12X variants use an MPO connector. The IBA standard builds upon many of the ideas seen in the more recent interface standards, but unlike the minimalist philosophy often seen elsewhere, IBA sets ambitious objectives across the board. With a very flexible architectural model, high throughput, and well defined interfaces for its manifold variants, the IBA standard promises to be an important growth path for the industry. As with many earlier standards, how well it fairs in the
market will depend largely upon the commitment of consortium members,
especially in compliance with the demanding requirements of the IBA
specification. The outcome remains to be seen. |