| An
Introduction to NFS Performance Part 1 |
| Originally published Spetember, 1995 |
| by
Carlo Kopp |
| © 1995, 2005 Carlo Kopp |
|
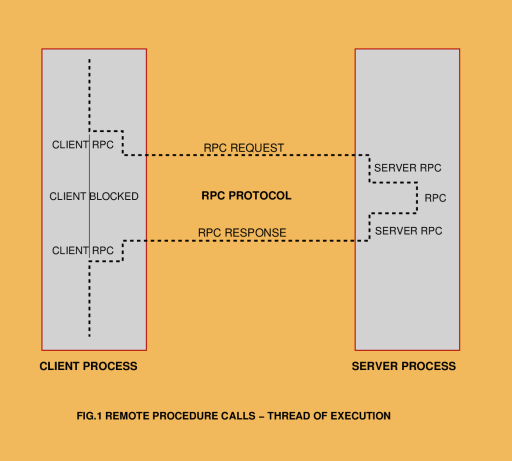
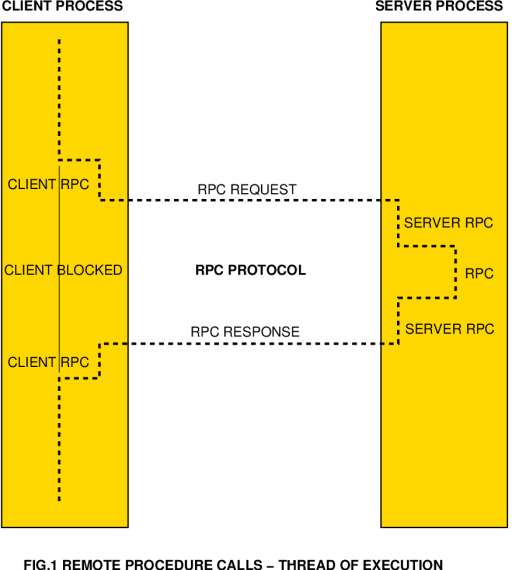
Sun's Network File System (NFS) file serving protocol has become in the last decade the defacto standard file serving protocol in heterogeneous Unix environments. Furthermore, the availability of a wide range of NFS client ports to non-Unix environments has meant that NFS is in many respects the only common medium for file serving functions across a heterogeneous computing environment. In practice this means that many sites will exploit the automated backup facilities in Unix, and employ the Unix file servers to support not only Unix NFS clients, but also PC NFS clients or other proprietary systems. While the model of a single centralised Unix host, or group of hosts, as a centralised site file server has many operational advantages, the resource it presents will in a great many instances become overburdened with traffic and as a result suffer performance problems. Because it is a central shared resource, any problems it experiences will be felt across the site. It is for this reason that NFS performance is in a modern distributed computing environment a critical factor, the importance of which should never be underestimated. In the light of emerging client server computing schemes such as CORBA, it is worth noting that many of the performance issues which impact NFS servers will also impact CORBA servers. CORBA is still evolving, and whileits Version 2.0 will see the adoption of a new Internet Inter-ORB Protocol (IIOP) which differs in many respects from the RPC based model of CORBA 1.x, either model will be very sensitive to host network performance. Therefore there is much to be gained from a good understanding of the mechanisms which impact performance. The NFS and RPC Protocols The NFS protocol was developed by Sun Microsystems in the early eighties, to support their paradigm of client server computing. NFS was the first major client server product to proliferate widely in the market, and is without doubt the most widely used at this time. NFS is built around the Remote Procedure Call (RPC) model. The RPC model is based upon the idea of out-of-process procedure calls, whereby some procedure calls are executed within the process binary, and some executed by another process. The simplest way of looking at this model is to visualise the thread of execution within the client process. This thread will jump from procedure to procedure within the client process, until it hits a remote procedure call. At this point it will jump off into RPC protocol code, which will bundle up the procedure arguments and transfer these, together with a specifier for the procedure type, over an InterProcess Communications (IPC) channel to the server process, which may be on the local host but more often sits upon a remote host. Other pieces of RPC protocol code will then pass the procedure call an its arguments to a server process, which will then execute the call and return its results. These are then taken by the RPC protocol modules and transfered back to the client. The client will then resume its local thread of execution. This is a very trivial outline of what actually takes place within the bowels of the operating system. There are indeed a number of very obvious technical issues which must be addressed if such a scheme is to operate robustly, let alone efficiently. To address these technical issues, Sun designed the RPC protocol and its associated functional model, as well as the eXternal Data Representation (XDR) protocol which is a necessary part of the scheme. Client Server Binding - The Port Mapper The first and most obvious technical issue to be addressed in any client-server computing scheme is that of enabling the client to find the appropriate server process on the network. While finding a particular host is very straightforward in a TCP/IP environment, finding a particular process can be trickier. The simplest model in use is the "assigned port numbers" model, where particular server processes listen on specific network port numbers. This model evolved in the early days of Unix networking and is still used for most of the networked utility programs, maintenance protocols and services on a system. In any RPC scheme, the use of this simplistic model becomes problematic, as there is a finite address space for ports, and this address space would eventually become saturated. Another problematic issue is the management of port numbers, as a means is required to ensure that two or more different server processes do not end up sharing a single port number. Where different vendors bundle different networked applications on their flavour of Unix, this problem had the potential to become catastrophic. The resolution of this problem lies in the use of the portmapper model. In the portmapper model, port numbers from a pool of uncommitted ports are dynamically assigned to RPC server programs. A server which is starting will typically be given an arbitrary uncommitted port number, which it then registers with the portmapper process, in effect saying "this is where I live". In the RPC protocol, the client RPC implementation need only know about the address of the portmapper's port. It then communicates with the portmapper process, which will return the port number which is at the time assigned to the server being sought. The RPC client will typically cache the returned port number, so that any subsequent calls to the server in question go directly to the server's assigned port number. In this fashion, the overhead of finding the port number is only incurred once per session. The portmapper process is thus a critical system resource, the loss of which can cause havoc, as any of those who have experienced a portmapper crash can no doubt testify to. The portmapper protocol is defined in Sun's RPC Protocol Specification. XDR - eXternal Data Representation The second obvious technical problem to be addressed in a client server scheme is that of a common data representation across machines of different instruction sets. Different instruction sets in practice mean often different ordering of bytes in words (big-endian vs little-endian), as well as different word sizes, such as 16-bit, 32-bit and 64-bit. While 16-bit engines are becoming increasing scarce with the retirement of PC-AT platforms, we are now seeing the proliferation of 64-bit architectures, such as DEC's Alpha and Sun's newest SPARC architecture. There are two basic strategies which can be employed for dealing with this problem. The first could be described as "conversion on demand", where data is sent in the native format of the sending platform, together with an identifier for the architecture used, and is then converted by the recipient into its native format. This scheme has the advantage of efficiency in a heterogeneous environment, as only one conversion is required per transfer. It has the disadvantage of having to maintain tables of foreign architecture conversion parameters on every host, something which can get out of control, needless to say. The alternate strategy is that of using a protocol specific canonical format, whereby all data sent must be converted from a native format before sending and upon receipt. Where the canonical format is identical to the native format at both ends of the link, a minimal overhead is incurred. Where the canonical format differs at both ends from the native format, a conversion must take place at the receiving as well as the sending end, in both directions. This can as a result incur a significant computational overhead, particularly if the RPC application is transferring a lot of data, as in the instance of NFS. When Sun designed the XDR protocol, they specified a 32 bit
big-endian integer canonical format, with 8 bit bytes, and 64 bit
"hyper" integers. If your systems employ 32-bit big-endian
architectures, the XDR conversion overhead will be minimised (ie SPARC,
MIPS, 68k are efficient, Intel and VAX inefficient).
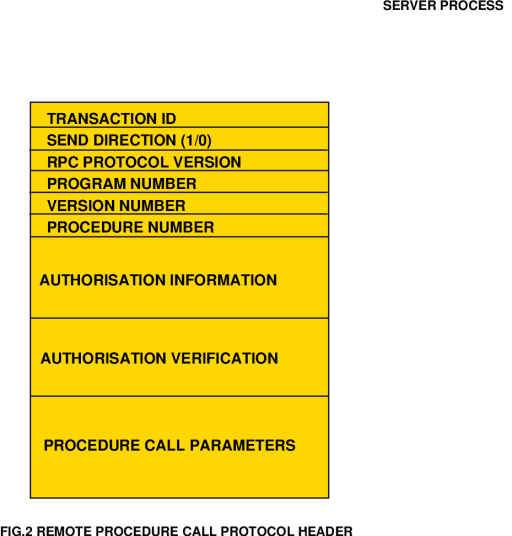
The RPC Protocol The RPC protocol is usually run over the Internet User Datagram Protocol (UDP) and is presented in XDR format. An RPC protocol header is comprised of a transaction identifier, send direction, RPC protocol version number, program number, version number, procedure number, authorisation and call parameter fields. Each of these serves a specific purpose and we will briefly review these to provide some insight into the design strategy employed. The Transaction ID uniquely identifies a service request from a client to a server. This is important where a client sends multiple requests, the replies to which may arrive out of order. The unique ID allows the replies to be matched up with the requests. In addition, a server can identify retries or repeated requests which may be produced by a client experiencing problems with the communication channel. The Send Direction identifies a request (RPC call) as 0 and a response (RPC reply) as a 1. The RPC Protocol Version Number is used to identify which version of the protocol is in use. This is to prevent different versions with potential incompatibilities from getting into difficulties on mutual access. The Program Number uniquely identifies the program to be accessed by the client, while the Version Number allows the scheme to accommodate more than on version of the program in question. This can be a very useful feature for supporting backward compatibility. Finally the Procedure Number uniquely identifies the procedure to be called within the specified version of the program. Two Authorisation Fields of up to 400 bytes each are also supported in the protocol header, interested readers are referred to RFC1050. Functionally the protocol, as noted earlier, follows a request-response or message oriented model. A request can be accepted by a server or rejected on the basis of unavailability, version mismatch, absent procedure or undecodable arguments.
The NFS protocol is an RPC application, and is supported over UDP, and also TCP in some implementations. As such it uses the XDR scheme for data representation. The protocol is comprised of a number of RPC procedures for executing operations on files or directories. NFS is an instance of a stateless server protocol, where the server retains no state information concerning the NFS operation. This strategy was designed to simplify recovery when a server crashes, as the server need not concern itself with the state of any operations which were in progress during the crash. The client simply retries the transaction and if the server is up again, receives the requested response. The most important data type used in the NFS protocol is the File Handle (fhandle). The file handle is produced by the server on a reference to a file or similar object on the server platform, and contains all the information necessary to uniquely specify the object. The client is returned a file handle on every access, and must use this handle for every access to the object in question. The client is not allowed to manipulate the handle, and in effect must treat it as a number like identifier. On a Unix server the file handle will store the inode number of the file, and the major and minor device numbers associated with the driver of the device on which the inode is resident. The NFS protocol recognises five separate file object types. These are regular files, directories, block files, character files and symbolic links. File attributes may be returned in a fattr structure, which is very similar to the Unix stat structure returned by the stat() family of system calls. The NFS protocol (V.2) has fifteen RPC procedures which allow a client to carry out most of the typical operations to be done on a local file. These are:
As is apparent, the NFS protocol meshes very nicely with a Unix environment, and this has been one of the reasons for its popularity. Sun had very cleverly made the source code to the RPC protocol publicly available, as well as the specifications for the NFS protocol and associated mount protocol. Modern Unix systems transparently integrate NFS through the file descriptor / table entry and vnode mechanism at the client end, as result an application on the client need not concern itself with the location of the file it is manipulating. For completeness, it is worth restating that a SVR4 vnode contains a v_op pointer to a structure containing filesystem specific operations. There are no less than 37 operation types supported in a vnode, and 36 of these are available for an NFS filesystem. Whereas an operation against a vnode for a local filesystem will result in local system calls being invoked, if the vnode is associated with an NFS filesystem, the operations will invoke the appropriate NFS RPC procedures to manipulate the file or directory in question. Where the client and server are both Unix systems, the mechanism will operate very cleanly. Where one or both are proprietary platforms, some additional work may be required to camouflage the idiosyncrasies of the non-Unix environment used. NFS and its underlying RPC mechanism are under the skin somewhat more complex than may be apparent from a casual glance. The task of making a remote file accessible in a fashion which is transparent to a user application is not entirely trivial, and this is in turn reflected in the plumbing required for the task. Part 2 of this feature will look in more detail at the performance issues which arise when running NFS, and what measures a system administrator can take to analyse, diagnose and if possible improve the performance of his or her client and server platforms. |
| $Revision: 1.1 $ |
| Last Updated: Sun Apr 24 11:22:45 GMT 2005 |
| Artwork and text © 2005 Carlo Kopp |