
| Wide Area Networking - The Issues |
| Originally published November, 1997 |
| by
Carlo Kopp |
| © 1997, 2005 Carlo Kopp |
|
Wide Area Networks (WAN) have become a fundamental part of the modern systems paradigm, and have seen a level of growth without precedent in this industry, over the last several years. The only paradigm which compares in sheer scale is the proliferation of cheap desktop computers. The WAN paradigm has has its origins in the early Arpanet, the forerunner of the modern Internet. It is without doubt that the Arpanet model set the direction of much development work, and contemporary WAN technology is firmly wedded to many of the basic concepts first brought to life in Arpanet. Today we see WAN technology used by common carriers, such as ISPs, both large and often small, as well as by private corporate networks. Clearly, many central issues will be common to all WANs, and the purpose of this discussion will be to look at many of the core issues which an organisation must address when dealing with this technology. Functionality The starting point for any such discussion must be that of what purposes the WAN is to serve, as this has an important bearing on issues such as performance required, and protocols supported. For a common carrier, the primary purpose of the WAN is to concentrate traffic from a large number of sites into a feed point into the larger Internet. This means that HTML traffic, with a rich graphics content, will be the primary component of the load. Response time will be a very important issue, and traffic will be extremely bursty by its very nature. For a private WAN, the requirement will certainly include HTML, in varying proportions, subject to the sites in question, but it will also need to carry respectable proportions of other traffic, such as remote logins and remote file access. Since many sites are tied by history to legacy applications and platforms, as well a proprietary file serving protocols, the ability to carry multiprotocol traffic is an essential part of the task. Particularly PC-centric sites using the wide range of proprietary protocols, as well users of mainframe hosted proprietary operating systems and associated networking schemes (eg SNA) fall into this category. Response and throughput performance will be issues very often, but there is less competitive pressure in a private network environment, since the client base is for all practical purposes captive. Other functional issues are beginning to come into play. One very important one is mobility, as many service subscribers and internal corporate clients will have a big interest in exploiting this emerging technological capability. Providing a mobile service, whether it is on-site or off-site, will add a significant number of additional headaches to the list which the network integrator must access. Performance vs Cost Issues From a strictly technological perspective, performance is going to be he central issue in any WAN design. Poor design and analysis could mean that even the best equipment once integrated into a system may provide mediocre throughput and response times. Given the significant expense involved in any large WAN deployment, getting the design right or wrong can make the difference between beaming clients, or firings and lawsuits. The author recalls a major tender many years ago, for the supply and integration of a large state wide WAN, to link up a significant number of regional and suburban branch offices to a central site with its obligatory battery of mainframes and storage. The client produced an RFT document, in which the network topology to be used was specified, and the bandwidth to be used on each link was specified. As it turns out, the client's starting point for the exercise was - these are the going Telecom rates for fixed tie lines, therefore which topology minimises the Telecom rental charges. Within itself this would not have been an issue, except for the fact that the same RFT also mandated a non-negotiable response time performance requirement, specified as "N seconds after a keystroke for transaction type X, the screen shall be repainted". Even a trivial queuing model analysis for the network indicated that the mandated topology and link speeds, regardless of the response times at the mainframe end, made this requirement impossible to meet, whatever networking equipment was to be used for this. After much collective protestation by all bidders, the client conceded that the performance requirement was more important than the topology requirement. At this point the various bidders produced a more appropriate topology model, calculated the required link bandwidths to achieve the specified performance, picked the appropriate configurations of routers and network terminals/modems and submitted their bids. The end product was fairly consistent in terms of price and complexity across the several bidders on the project, with a large number of multi-Megabit/s links, big and expensive routers and an aggregate budget for the project several times greater than the client's expectations. As a result, the whole project was shelved and to the author's knowledge, died a quiet death. Many manhours expended by the various bidders for no return to anybody, and many red faces in the client's IT department. Many readers in the networking community will no doubt chuckle having read this, having had this experience many times over. What does it tell us ? That the relationship between cost and system throughput and response time performance is highly sensitive. The real lesson to be learned here is that large WAN design is not an ad hoc task and even if the WAN is to grown incrementally, the sizing of the whole system must be carefully analysed and mapped out beforehand. Within itself this is a non-trivial task, and something not to be attempted by the amateur systems integrator. The central issue for many organisations will be therefore finding the proper balance between performance and cost in their WAN, since excursions in either direction will cause pain of one or another variety. Cost comprising acquisition costs of equipment, support costs and rental charges for links, the task of even accurately costing a WAN project can be fraught with dangers. Performance analysis is yet another can of worms, since the statistical properties of the traffic do not always lend themselves to simple and accurate performance prediction (doubters are directed to the Bellcore paper), and the interaction of host performance in system performance must be accounted for. Is there a simple recipe for dealing with this problem ?
Should an IT manager simply throw his hands up in despair and throw
himself down at the mercy of the vendors ? Or should he sell his soul to
an expensive consultant ? Or should he go out and hire a senior network
design engineer ? There is of course no simple answer to this problem,
which will continue to be an issue for many sites, especially those
with tight IT budgets. Whether an organisation chooses to go the
do-it-yourself route, or opt for a turnkey or semi-turnkey solution,
there are many things which can be done to minimise risks and introduce
a good measure of predictability into the final outcome. 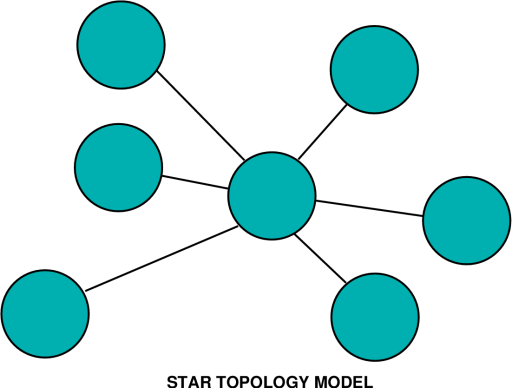 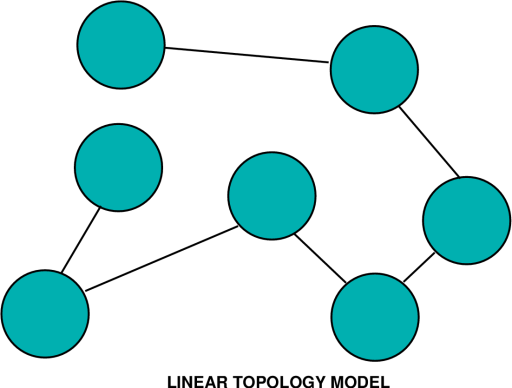  
Planning and Analysis Issues The starting point for any risk minimisation effort is thorough planning, mapping out well ahead what growth requirements can be expected, where and with how much bandwidth. This will be whether an organisation is creating itself a new WAN, or incrementally growing an existing system. In the latter case, the task is much simplified, since the planner will have the advantage of knowing not only client expectations, but also being in the position to measure existing throughput and response time performance. When starting from scratch, the latter must be modelled and estimates made, which increases the risk of not getting it quite right. Once we have an idea of what traffic load we can expect between which nodes (sites) in the planned network, we can then star to analyse the required bandwidth to achieve the desired performance. Routers are by their basic nature queuing devices, the archetypal packet store and forward black box. Most router products are today specified with a packet forwarding delay, which depends on the devices' instantaneous traffic load. Lightly loaded, a router will forward packets with a delay very close to the nominal forwarding delay. As traffic load builds up, the delay progressively increases, subject to queuing theory. So for any any given router type, we can fairly easily establish an estimate of delay under load. Router performance can be exceptionally good with the latest generation of equipment, which often uses dedicated hardware rather than a software driven microprocessor, to route the packets. The next issue to address is that of the network topology. Topology is often critical, since appropriate choice can deliver good performance at a sensible price, and inappropriate choice can, as discussed earlier, produce pretty much a distater. The simplest topology model is the star, where a central site has dedicated links to each and every remote site. To minimise cost the central node is situated at a point which is geographically central to the network. Traffic between remote sites passes at most through three routers, one each at the remote sites, and one at the central site. From a pure performance perspective, in a multinode network, this would be the optimal solution. In practice, large WANs seldom use this topology since the cost penalties of long haul high speed links are usually prohibitive and as a result, unaffordable (consider a national network with a central node in Melbourne or Adelaide, and all other nodes routing to the central node). Probably the cheapest alternative topology model is a linear topology, which minimises the link cost by connecting the nodes in a string (consider an arrangement where links connect sites in Brisbane, Sydney, Melbourne, Adelaide and Perth). In this model, we have acceptable or very good performance for nodes which are adjacent, but declining performance for sites at the extremities of the network. (in this instance a Brisbane-Perth connection must traverse no less than five routers). Other than the queuing delay in the routers, long traffic must also share links with traffic between adjacent nodes (in this example the Sydney-Melbourne link carries also all traffic between Brisbane and nodes other than Sydney, as well as the Sydney-Melbourne traffic). In practice, network traffic loads vary very much subject to the purpose for which the WAN is used. A common carrier, such as an ISP, will typically try use a topology designed to minimise the number of hops between the majority of traffic load generating nodes and the feed into the US Internet. Running a traceroute on a US site from wherever you are is a good indication of how well your ISP has addressed this problem. A private network, such as that used by a government department or a company, if dedicated to internal traffic, should be structured to minimise if possible the number of hops between the central server site, and the sites which generate the most traffic load. With a propensity for employees in many sites to browse the web (for revenue generating or non revenue generating reasons), traffic loads can become skewed toward the site which ties into the Internet. If internal web sites are used, producing internal mirror sites at remote locations can do much to alleviate long haul traffic loads. So it is not difficult to see that there are plenty of parameters to play with when designing a new WAN, or extensions to an established WAN. An important caveat in this game is knowing what your traffic level and type is, and what performance limitations are acceptable to your users. Once we have produced a workable topology, analysed traffic loads and estimated performance, we can begin to see what the price-performance relationship for our WAN backbone is likely to be. At this point we can start addressing other, more mundane but no less important issues. Reliability Issues Reliability is a subject area often ignored until a piece of equipment is down and revenue is lost, and every reader will certainly recall at leat one such situation. Often regarded to be a boring subject area beneath the technology centred network engineer, reliability is vital in particular for WANs carrying financial transaction traffic, or operationally vital data. There are several important issues to be addressed in the WAN reliability game. One is the reliability of individual equipment items, site-to-site communications links, and the on-site supporting infrastructure (power, cooling), another is the ability of the topology in use to operate with link outages, and finally are there any other potential points of failure in the WAN. The first group of issues are classical reliability engineering problems, which can be readily addressed by on-site redundant spares, hot or cold, backup power and cooling, and with good numbers on hand it is not difficult to calculate reasonably accurate probabilities of failure for any site in the system. The ability of any given topology to withstand link outages is a more complex problem, and again the provision of redundant links is the most robust approach to the problem. The downside with all redundancy is of course cost, if you want a fully redundant system you will end up doubling the costs of your links and if a fast cutover is required, also on site routing hardware. A common strategy for WANs is therefore to adopt "degraded performance redundancy", where the spare or backup links are much slower, and cheaper, and only used should the primary link go down. If you are buying these from a carrier, it is worth checking to see that they don't both occupy the same cable ! Internet Protocol networks can also experience nasty reliability problems due to failures in ancillary, higher level services. The most important and critical of these is the Domain Name Service (DNS), which maps names into IP addresses. Redundant name server hosts are a must for larger WANs, as anybody who has lost his one and only name server host can no doubt testify to. A useful strategy is to have at least a pair of name servers, primary and secondary, on each major site in the WAN. Arguably a messy overhead to maintain, but another example of the dual nature of redundancy - you get what you pay for. Needless to say piggyback support for mobile nodes is an issue within itself, complicated by the fact that IP support for mobiles is still very much in the definition phase. Protocol Issues The protocol issue is one of critical importance at this time, since we are in a period where much of the world is using IPv4, IPv6 is to soon deploy, and there are still a very large number of proprietary hosts and associated protocols in service. Then of course we also have to deal with the issue of vendor proprietary protocols between routers, often much more capable than IP, and whether to therefore opt for a "pure" IP network, or a hybrid network. In a multiprotocol environment a proprietary router-router protocol, with the ability to transparently encapsulate the wide range of proprietary LAN protocols, is often a much cheaper albeit less elegant solution for dealing with the heterogenous platform problem. The protocol issue does not stop with the network transport protocols, because we also consider the lowest level datalink protocols which we run our routers across, or whether to even opt for a protocol at this level. Frame Relay for instance, conceptually a cut down high speed derivative of X.25, can transparently carry IP concurrently with still very widely used legacy protocols like SNA. Do we therefore opt to use a Frame Relay service to interconnect our nodes, and run the legacy protocols in parallel with our IP traffic. Or do we acquire a suitable black box and either tunnel our SNA through IP, or otherwise do a protocol conversion to the standard IP ? Do we use simple synchronous bit pipes between our sites, or do we opt for the slightly more sophisticated ATM protocol ? Another issue in the domain of protocols is the nature of our traffic. A good example of an emerging problem will be the carriage of video traffic over WANs. Video is typically carried using a compression protocol such as MPEG or H.263/264, which cleverly compresses the picture and sound into a packet stream, typically with a highly variable packet rate. Inherently bursty, such protocols will require some headroom in bandwidth to ensure that even transient router congestion does not cause picture dropouts. Do you want your Managing Director's "videophone over IP" connection to a vital overseas client to clag up in the middle of critical commercial negotiations ? The complexity of the currently available protocol suites and the diversity of traffic types clearly indicates that there are no simple rule of thumb recipes for dealing with this situation. The most workable approach is to prioritise what your criteria are and try to select the best balance between price and performance/utility. Ideally, an IP centred solution should be used to provide a maximum of long term compatibility. However, if your site largely comprises SNA networked mainframes, and PCs running proprietary networking protocols, it is likely to be a hard sell to management. Long Term Issues We can expect, in the longer term, to see a greater diversity of high level applications and protocols to be run over the humble IP, which will soon transition to IPv6. Open systems warriors have long anticipated (and hoped for) the decline and extinction of the proprietary networking protocols, but if current trends continue, this is still some years away. For the next decade we can therefore expect to see proprietary protocols live on, simply because many legacy application sites can neither afford to, or even want to, part with what they love and know. The large scale deployment of ATM for wide area services will see a toward ATM interfaces on routers, where this has not happened already. With a standardised ATM interface into the telecommunications world, some of the existing router to line interface issues will vanish. Bandwidth is likely to decline in cost with increasing capacity tracking increasing demand. How dramatic this will be remains to be seen. The issues which confront today's IT Managers, Network Managers and Network Architects are anything but trivial, and given current trends are unlikely to become any simpler over the next decade. We have yet to see the WAN paradigm saturate in market deployment, so without any doubt we can say that interesting times lie ahead. |
| $Revision: 1.1 $ |
| Last Updated: Sun Apr 24 11:22:45 GMT 2005 |
| Artwork and text © 2005 Carlo Kopp |