Selected Internet use statistics from 1990 to 2006 (from Gap Minder).
FIT3084: Behind
the (World Wide) Web
In the previous lecture:
In this lecture:
What is the Internet?
|
Selected Internet use statistics from 1990 to 2006 (from Gap Minder). |
Have a look at Gap Minder in your own time to answer the following questions.
Which country currently has the largest percentage of Internet users?
Which country has the largest number of Internet users? How long as this been the case?
Which country has the lowest percentage of Internet users?
What do these statistics mean for you as a web site publisher?
How does wealth relate to Internet usage around the world?
|
Transmission Control Protocol/Internet Protocol is a low-level protocol by which Internet computers of different makes, models and operating systems communicate. |
How is information retrieved from the Internet?
Use one of the (many) high-level protocols and its software user interface.
As well as Gopher, WAIS... find out what these are (were) by doing a little web surfing!
File formats: storing information on the Internet
There are thousands of different file formats.
A file format is a particular way of storing or ordering information in a file.
The specification of a file format includes information regarding what goes into a file, and the order it is written/read.
Here are some you might find on the web:
|
|
Special software is needed to view, hear, play, read, interpret or edit any file format.
|
The problems for Internet information retrieval.
|
How does the WWW relate to the Internet?
 |
The WWW began in 1989 at CERN lab to help simplify the retrieval of information from the net. See the WWW's 20th birthday celebration page. |
The idea underlying the WWW is that a user is able to transparently jump around the global Internet retrieving information without worrying about the 4 problems posed above.
Now, to answer the questions above...
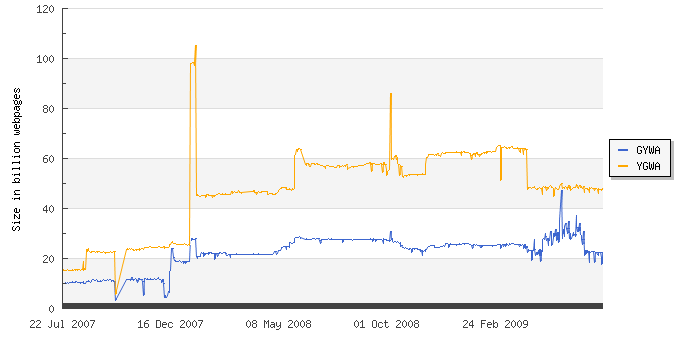
The size of the indexed WWW
|
GYWA = Sorted on Google, Yahoo!, Windows Live Search (Msn Search) and Ask The Indexed Web contains at least 22.53 billion pages (Monday, 20 July, 2009) |
Making a personal mark on the WWW.
Originally, the WWW contained information posted by a few companies, research organisations or university academics who had or hired resources and skill to build a web-site and set up a web-server.
 |
Personal homepage: a homepage was the original way to make a personal mark on the WWW. These were always "under construction" and often out of date due to the amount of time it took to maintain them. Nevertheless, they are still popular due to their flexibility and the availability of software to edit HTML web pages easily and in a WYSIWYG fashion. |
|
 |
Social networking. |
|
 |
Blog. |
|
Micro-Blog. |
||
Content sharing. |
||
Other Notable Applications of the WWW.
Find and buy goods from large retailers anywhere around the world and have them shipped to your door. |
|
Find and buy (especially second-hand) goods from small retailers anywhere around the world and have them shipped to your door. |
|
Pay for things securely over the Internet using a credit card. |
|
Find places, look at street views and aerial photographs of (nearly) anywhere! |
|
Do your banking and pay your bills online. |
|
Receive current data on currency exchange rates, stock prices, traffic flow, weather, sporting results... |
Identifying files on the Internet. |
 |
The Internet is a global network (of networks) of computers.
Every computer on it has a unique numerical address (an IP address) and a people-friendly equivalent. You can find out the IP address of a machine using the UNIX host command (type man host at a UNIX prompt to see how it works).
130.194.64.140 ...is the numerical address for our department's old web server... shelob.csse.monash.edu.au
The Internet is divided into domains, and subdomains.
shelob |
is the machine name. |
csse |
is the Computer Science and Software Engineering subdomain. |
monash |
is the Monash University domain. |
edu |
indicates the address is educational. |
au |
indicates the address is Australian. |
Every file on a computer has a filename unique for that machine. When appended to the IP address of its host computer, every file on the Internet therefore has a unique name.
Steps for Retrieving Documents from the Web.
Computers on the Internet called name servers keep lists of numerical
IP addresses & people-friendly names and translate between them.
1) A web browser (client) sends a request using HyperText Transfer
Protocol (HTTP) for a document, specified by its unique name, to a remote
(server) machine.
The unique file name is specified within a Uniform Resource Locator (URL)...
Protocol://server_domain_name/file_path
The protocol may be omitted within some web browsers in which case HTTP is assumed.
Absolute URLs
http://www.csse.monash.edu.au/~aland/index.html
ftp://ftp.cs.monash.edu.au/pub/are absolute because they include a domain name and a path.
Relative URLs
index.html
../index.html
are relative because they specify a path and domain name by reference to (usually) the URL of the file currently open in the browser (often referred to as the base).Locations within documents
http://www.csse.monash.edu.au/~aland/index.html#chapter
index.html#fred
The text after the # symbols indicates a location within the document specified by the URL.
These locations are named whilst the document is being created. The #location is an optional part of a URL. When would it be useful?
2) A web server program on a remote machine always listens on a well-known port for incoming requests. (Port 80 for HTTP)
3) The web server checks client access privileges, if all is well, it
sends the requested document.
4) A browser displays the document retrieved from the server on the client machine
in human-readable form
A web document is anything accessed with a single request from a client to a server.
Try this in your own time...
| Commands to type. | Explanation. |
| telnet www.csse.monash.edu.au 80 | Telnet to the school's WWW server (on port 80) |
| GET /index.html HTTP/1.0 | Access the web page "index.html" using the GET command which the browser would normally do for you. Follow your command with two carriage returns. |
| >> The server should send you the HTML of file "index.html" | See? The protocol isn't magic, you can participate in it manually. |
©Copyright Alan Dorin 2009