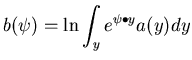This section describes an MMC algorithm suitable for problems where the likelihood function is unimodal and of fixed dimension. A simple algorithm for finding the region with minimum message length is described, along with a Newton-Raphson algorithm for finding the point estimate.
For the unimodal likelihood function case the minimising MMLD region can be found using Algorithm 1. This algorithm is based on Algorithm 1 from (Fitzgibbon, Dowe, and Allison, 2002a, page 12) but has been modified to use the more accurate message length approximation described in the previous section. The algorithm is fast and efficient requiring a single pass through the sample. It produces a single region.
Choosing the point estimate can be more difficult than finding the region. For continuous parameter spaces of fixed dimension the Newton-Raphson algorithm is suitable. The Newton-Raphson method requires an initial estimate,
![]() , for which we can use the element of the sample with maximum likelihood. Based on Equation 14, and using the notation
, for which we can use the element of the sample with maximum likelihood. Based on Equation 14, and using the notation
![]() , each iteration we update
, each iteration we update
![]() by solving the following linear system for
by solving the following linear system for
![]() :
:
| (18) |
![$\displaystyle J = \left[ \begin{array}{ccc} \sum_{\theta \in Q} f(x\vert\theta)...
...\hat{\vartheta_d}} \Bigl\lvert_{\hat{\theta}^{(k)}} \right) \end{array} \right]$](img57.png) |
(19) |
![$\displaystyle d\hat{\theta}^{(k)} = \left[ \begin{array}{c} d\hat{\vartheta_0}^...
...t{\vartheta_d}} \Bigl\lvert_{\hat{\theta}^{(k)}} \right) \\ \end{array} \right]$](img58.png) |
(20) |
In the following ``Dog Shock Experiment" example we have used a numerical approximation for the second derivatives in ![]() . In this example we also work in the canonical exponential form. The canonical exponential family (see (Bernardo and Smith, 1994)) of distributions have the following form
. In this example we also work in the canonical exponential form. The canonical exponential family (see (Bernardo and Smith, 1994)) of distributions have the following form
| (22) |
We now illustrate the use of the unimodal MMC algorithm on two simple problems taken from the Bayesian Inference Using Gibbs Sampling (BUGS) (Gilks, Thomas, and Spiegelhalter, 1994) examples. The first is a parameter estimation problem involving a generalised linear model for binary data. The second is a parameter estimation and model selection problem involving a generalised linear model with three plausible link functions. WinBugs13 is used to do the sampling in both examples with a 1000 update burn-in and a final sample size of 10000.
In this example we apply the unimodal MMC algorithm to the dog shock learning model from Lindsey (1994). While this example is quite trivial, it is intended to illustrate how the unimodal MMC algorithm works. The sampler for this example can be found as BUGS example ``Dogs: loglinear model for binary data". Lindsey (1994) analysed the data from the Solomon-Wynne experiment on dogs. The experiment involved placing a dog in a box with a floor through which a non-lethal shock can be applied. The lights are turned out and a barrier raised. The dog has 10 seconds to jump the barrier and escape otherwise it will be shocked due to a voltage being applied to the floor. The data consists of 25 trials for 30 dogs. A learning model is fitted to the data where the probability that the
![]() dog receives a shock
dog receives a shock ![]() at trial
at trial ![]() is based on the number of times it has previously avoided being shocked
is based on the number of times it has previously avoided being shocked ![]() and the number of previous shocks
and the number of previous shocks ![]() by the model
by the model
| (23) |
| (24) |
The unimodal MMC algorithm was run on the output from the BUGS program. The contents of the sample and the optimal region are shown in Figure 1. The message length of the region is 276.49 nits. The region contains 82 percent of the posterior probability. For this simple problem the message length and shape of the region is purely academic since there are no issues of model selection. We are more interested in the point estimate for the region. The following quantities are required for the Newton-Raphson point estimate algorithm (using notation from Equation 21)
| (25) | |||
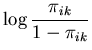 |
(26) | ||
| (27) | |||
| (28) | |||
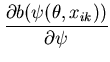 |
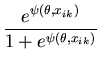 |
(29) | |
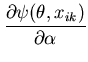 |
(30) | ||
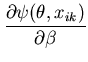 |
(31) | ||
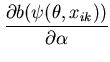 |
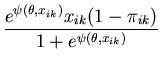 |
(32) | |
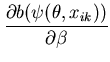 |
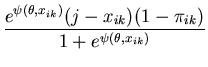 |
(33) |
The Newton-Raphson algorithm converged after six iterations to the estimates
![]() and
and
![]() . The estimate for
. The estimate for ![]() corresponds with the posterior mean reported by BUGS and the maximum likelihood estimate from Lindsey (1994) to three decimal places. The estimate for
corresponds with the posterior mean reported by BUGS and the maximum likelihood estimate from Lindsey (1994) to three decimal places. The estimate for ![]() differs only in the third decimal place and lies above the mean and below the maximum likelihood estimate as can be seen in Figure 1.
differs only in the third decimal place and lies above the mean and below the maximum likelihood estimate as can be seen in Figure 1.
The epitome for this example contains only a single entry with weight 1
| (34) |
![\includegraphics[width=0.6\textwidth]{/home/leighf/static/Paper-PostComp/dogs1}](img101.png)
|
In this example we use the unimodal MMC algorithm to perform model selection for the BUGS example ``Beetles: logistic, probit and extreme value (log-log) model comparison". The example is based on an analysis by Dobson (1983) of binary dose-response data. In an experiment, beetles are exposed to carbon disulphide at eight different concentrations (![]() ) and the number of beetles killed after 5 hours exposure is recorded.
) and the number of beetles killed after 5 hours exposure is recorded.
Three different link functions for the proportion killed, ![]() , at concentration
, at concentration ![]() are entertained
are entertained
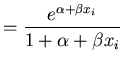 |
Logit | (35) | |
| Probit | (36) | ||
| CLogLog | (37) |
Dobson (1983) used the log-likelihood ratio statistic to assess the three link functions for goodness of fit. The test showed that the extreme value log-log link function provided the best fit to the data. We ran the unimodal MMC algorithm on 10000 elements sampled from the posterior for each link function. The message lengths and corresponding normalised weights for each link function are given in Table 1. We see that MMC also provides strong support for the extreme value log-log link function, giving it a weight of 0.9. MMC gives more than twice the weight to the probit link compared to the logit link function. This is in contrast to the log-likelihood ratio statistic that gives only slightly more support for the probit model. From the table we can deduce that the peak of the probit model likelihood function contains more probability mass that that of the logit model. In other words the logit model gets less weight by MMC because the parameters lie in a region with slightly less posterior probability mass than the probit.
The epitome for this example contains entries corresponding to each link function
| (38) |
| Link | 1st part length | 2nd part length | Message length | Weight |
|---|---|---|---|---|
| Logit | 2.098 nits | 186.857 nits | 188.956 nits | 0.03 |
| Probit | 1.729 nits | 186.219 nits | 187.949 nits | 0.07 |
| CLogLog | 2.145 nits | 183.310 nits | 185.456 nits | 0.90 |