This section describes an algorithm suitable for variable dimension posterior distributions. Unlike the simple unimodal algorithm we must incorporate a Kullback-Leibler distance acceptance test, so that regions contain only models that are similar. Such a constraint follows from Wallace's MMLA approximation (see, e.g. (Fitzgibbon, Dowe, and Allison, 2002a, section 2.2)). This also ensures that the MMC instantaneous codebook corresponds to an epitome with BPC properties. We therefore augment the likelihood-based acceptance rule (Equation 12) to include the following requirement
In previous work the basic unimodal algorithm was modified to include this Kullback-Leibler distance acceptance rule and to make multiple passes through the sample (Fitzgibbon, Dowe, and Allison, 2002a, page 14). While this algorithm was found to be satisfactory for the univariate polynomial problem it was applied to, we found that the regions refused to grow for the change-point problem that we consider later in this section. The problem was due to the discrete parameter space - the Kullback-Leibler acceptance rule stopped the regions from growing.
Therefore we have devised a slightly different algorithm that does not suffer from this problem. The algorithm consists of two phases. In the first phase we apply the unimodal algorithm to the sample recursively. That is, we start the unimodal algorithm and keep track of which elements of the sample have been allocated. Once the first region has been formed we store the results and restart the algorithm on the unallocated elements of the sample. This is repeated until all elements of the sample have been allocated to a region. We therefore end up with a set of regions:
![]() . Since these regions have been formed using the unimodal algorithm some regions will not be pure, they will contain models that are dissimilar (i.e., they will violate Equation 40). We therefore enter phase two of the algorithm where we recursively estimate the point estimate for each region and reassign elements between regions. The recursion stops when no reassignments were made in the last iteration. The reassignment between regions is based on Kullback-Leibler distance. For each element of each region we test whether there is a region whose point estimate is closer in Kullback-Leibler distance. If there is and the element passes the Kullback-Leibler distance acceptance rule (Equation 40) for the candidate region then the element is moved to the candidate region. Phase two of the algorithm is given as pseudo-code in Figure 2. After phase two of the algorithm has completed we are left with an instantaneous MML codebook which defines an epitome having BPC properties.
. Since these regions have been formed using the unimodal algorithm some regions will not be pure, they will contain models that are dissimilar (i.e., they will violate Equation 40). We therefore enter phase two of the algorithm where we recursively estimate the point estimate for each region and reassign elements between regions. The recursion stops when no reassignments were made in the last iteration. The reassignment between regions is based on Kullback-Leibler distance. For each element of each region we test whether there is a region whose point estimate is closer in Kullback-Leibler distance. If there is and the element passes the Kullback-Leibler distance acceptance rule (Equation 40) for the candidate region then the element is moved to the candidate region. Phase two of the algorithm is given as pseudo-code in Figure 2. After phase two of the algorithm has completed we are left with an instantaneous MML codebook which defines an epitome having BPC properties.
We now illustrate the use of the algorithm for a multiple change-point problem.
We now apply a multiple change-point model to synthetic data. In order to apply the MMC algorithm we require a sample from the posterior distribution of the parameters and a function for evaluation of the Kullback-Leibler distance between any two models. The sampler that we use is a Reversible Jump Markov Chain Monte Carlo sampler (Green, 1995) that was devised for sampling piecewise polynomial models by Denison, Mallick, and Smith (1998). The sampler is simple, fast and relatively easy to implement. The sampler can make one of three possible transitions each iteration:
We fit constants in each segment and use a Gaussian distribution to model the noise. However, rather than include the Gaussian parameters in the sampler we use the maximum likelihood estimates. This means that the only parameters to be simulated are the number of change-points and their locations. Use of the maximum likelihood estimates required us to use a Poisson prior over the number of change-points with
![]() .
.
The Kullback-Leibler distance is easily calculated for the piecewise constant change-point model and has time complexity that is linear in the number of change-points.
The function that we have used in the evaluation is the ``blocks" function from (Donoho and Johnstone, 1994). The function is illustrated in Figure 2 and consists of eleven change-points over the domain ![]() . We added Gaussian noise to the blocks function with
. We added Gaussian noise to the blocks function with
![]() for all segments. Experiments were conducted for two data sample sizes:
for all segments. Experiments were conducted for two data sample sizes: ![]() (small) and
(small) and ![]() (large). For each of these data samples we simulated 500,000 change-point models after an initial burn-in period of 10000. Every one-hundredth element of the sample was kept, thus reducing the usable sample size to 5000. We then applied the MMC algorithm to each sample.
(large). For each of these data samples we simulated 500,000 change-point models after an initial burn-in period of 10000. Every one-hundredth element of the sample was kept, thus reducing the usable sample size to 5000. We then applied the MMC algorithm to each sample.
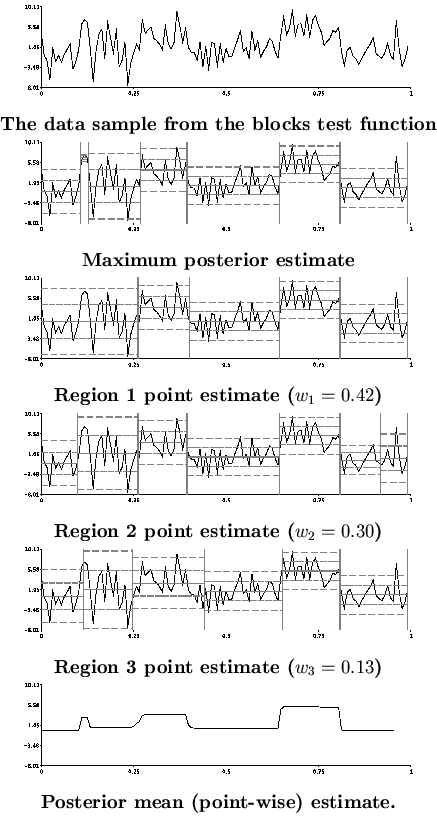
The main results for the small (![]() ) data sample size experiment can be seen in Figure 3.
This figure shows the data sample from the blocks function with
) data sample size experiment can be seen in Figure 3.
This figure shows the data sample from the blocks function with
![]() and
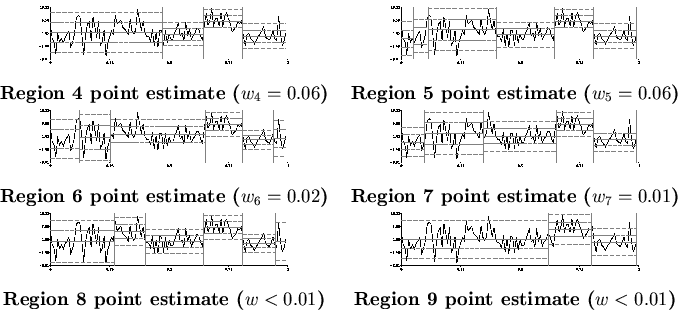
and ![]() . The element of the sample with maximum posterior probability (maximum posterior estimate) is also shown along with the three regions with the greatest weight, and the posterior mean estimate of the function. The epitome contained nine regions. The remaining regions (4-9) are shown in Figure 4. In the figures a change-point is marked using a vertical bar, and for each segment the mean and one and two standard deviation bars are shown allowing a change in the mean or standard deviation estimates for a segment to be easily seen.
. The element of the sample with maximum posterior probability (maximum posterior estimate) is also shown along with the three regions with the greatest weight, and the posterior mean estimate of the function. The epitome contained nine regions. The remaining regions (4-9) are shown in Figure 4. In the figures a change-point is marked using a vertical bar, and for each segment the mean and one and two standard deviation bars are shown allowing a change in the mean or standard deviation estimates for a segment to be easily seen.
With such little data we do not expect the true blocks function to be accurately estimated. The point estimates for regions 1-9 are all reasonable models of the data and represent a good degree of variety. The maximum posterior model closely fits the data in the second segment and would be expected to have a very large Kullback-Leibler distance from the true model. We see that none of the point estimates in the MMC epitome make this mistake.
The point estimates for regions 1 and 7 contain the same number of change-points, yet region 1 is given 42 times the weight of region 7 (
![]() and
and
![]() ). The main difference between the two is in the location of the first two change-points. This illustrates the need for methods to be able to handle multimodal posterior distributions and likelihood functions as this detail would be lost by simply looking at the modal model for each model order. This also occurs for regions 3, 5, 6 and 8, which all contain five change-points.
). The main difference between the two is in the location of the first two change-points. This illustrates the need for methods to be able to handle multimodal posterior distributions and likelihood functions as this detail would be lost by simply looking at the modal model for each model order. This also occurs for regions 3, 5, 6 and 8, which all contain five change-points.
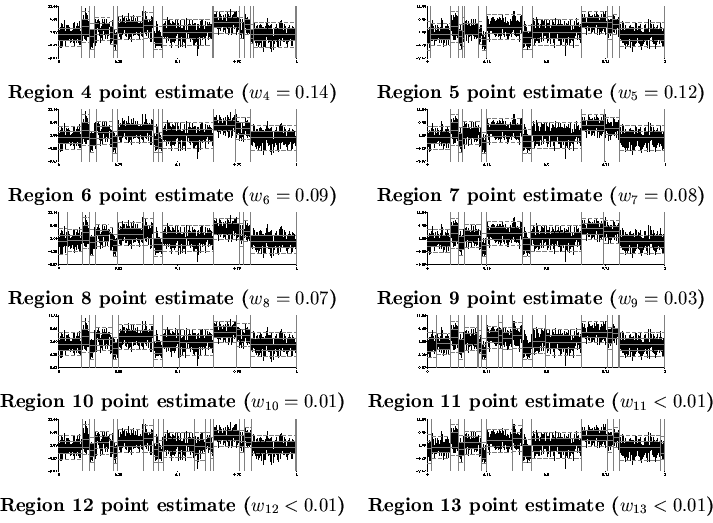
The main results for the large (![]() ) data sample size experiment can be seen in Figure 5. In this MMC epitome there were 13 regions. Regions 4-14 are shown in Figure 6. In these results we see that the maximum posterior estimate is quite reasonable but lacks one of the change-points that exists in the true function. The point estimate for region 1 is able to detect this change-point and looks almost identical to the true function. The point estimates for the other regions (2-13) look reasonable and tend to increase in detail. Some of them contain superfluous change-points. This does not damage their predictive ability or Kullback-Leibler distance to the true model, but can be distracting for human comprehension. This problem is discussed further in Section 7.2.
) data sample size experiment can be seen in Figure 5. In this MMC epitome there were 13 regions. Regions 4-14 are shown in Figure 6. In these results we see that the maximum posterior estimate is quite reasonable but lacks one of the change-points that exists in the true function. The point estimate for region 1 is able to detect this change-point and looks almost identical to the true function. The point estimates for the other regions (2-13) look reasonable and tend to increase in detail. Some of them contain superfluous change-points. This does not damage their predictive ability or Kullback-Leibler distance to the true model, but can be distracting for human comprehension. This problem is discussed further in Section 7.2.
For these examples we have found that the MMC algorithm can produce reasonable epitomes of a variable dimension posterior distribution. For both examples, ![]() and
and ![]() , we found that the point estimate for the region having the greatest weight in the epitome was closer to the true function than the maximum posterior estimate. We also find that the set of weighted point estimates provides some insight into the sample from the posterior distribution of the parameters and ultimately into the posterior distribution itself. We would also expect that using the set for approximating posterior expectations would be highly accurate.
, we found that the point estimate for the region having the greatest weight in the epitome was closer to the true function than the maximum posterior estimate. We also find that the set of weighted point estimates provides some insight into the sample from the posterior distribution of the parameters and ultimately into the posterior distribution itself. We would also expect that using the set for approximating posterior expectations would be highly accurate.
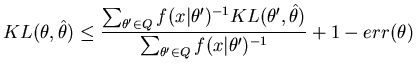

![\includegraphics[width=0.7\textwidth]{/home/leighf/static/Paper-PostComp/blocks}](img115.png)